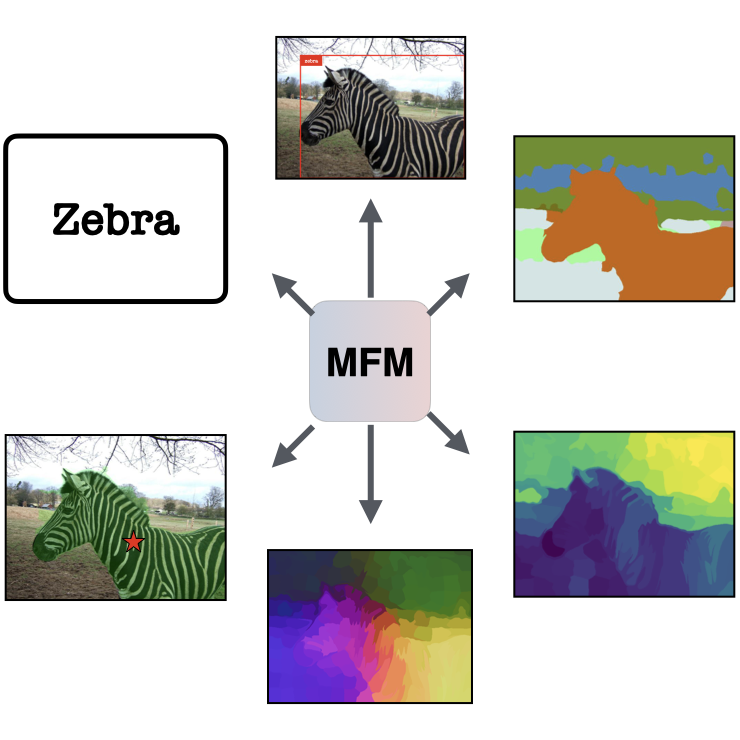
We benchmark top multimodal models like GPT-4o and Gemini on standard vision tasks using a prompt-based framework. While these models are strong generalists, especially on semantic tasks, they still trail behind specialized vision models, particularly in geometry.
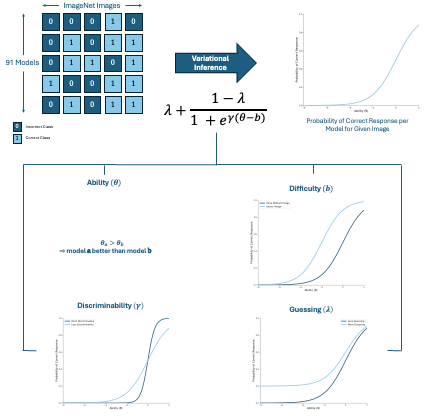
We use Item Response Theory (IRT) to assess model
calibration, select informative data subsets, and
demonstrate the usefulness of various latent parameters
for analyzing and comparing models and datasets in
computer vision.