|
Rahul /ɹɑːhuːl/ Ramachandran /ɹɑːmʌtʃʌnðɹʌn/ Hi! I'm a first-year Ph.D. student at the University of Illinois Urbana-Champaign, where I'm fortunate to be advised by Prof. Saurabh Gupta. I'm excited about robot learning, and am currently interested in sim-to-real transfer for manipulation, particularly for non-prehensile tasks. Previously, I finished my Bachelor's in Computer Science at IIT Hyderabad. I've had the privilege of working with Prof. Vineeth N Balasubramanian at IITH and with Prof. Amir Zamir at EPFL. |

|
|
Ph.D. in Computer Science, 2030 (Expected)
Bachelor's in Computer Science, 2025
|
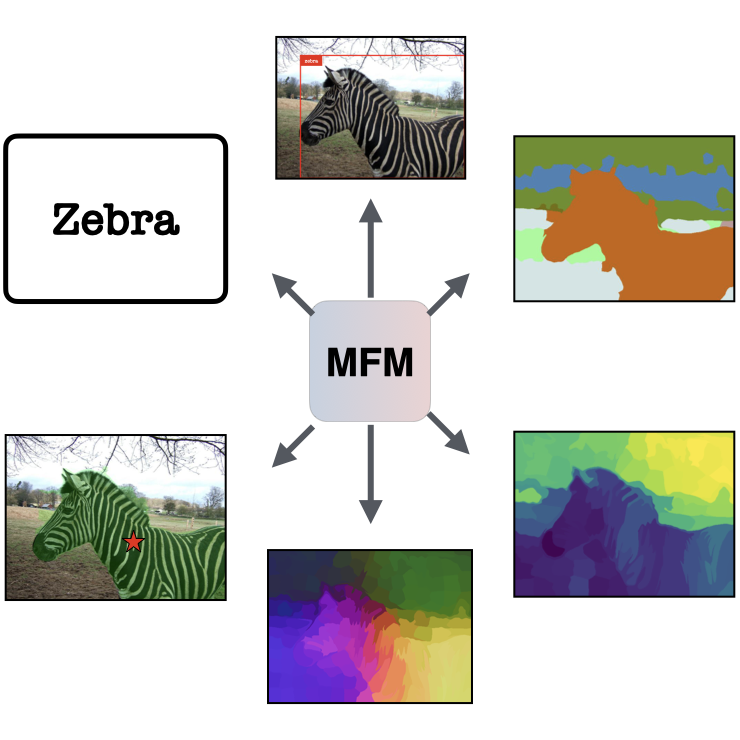
Rahul Ramachandran, Ali Garjani, Roman Bachmann, Andrei Atanov*, Oğuzhan Fatih Kar*, Amir Zamir*
ICLR, 2026
description
We benchmark top multimodal models like GPT-4o and Gemini on standard vision tasks using a prompt-based framework. While these models are strong generalists, especially on semantic tasks, they still trail behind specialized vision models, particularly in geometry.
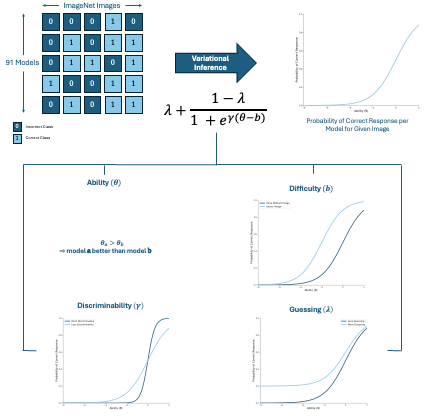
Rahul Ramachandran, Tejal Kulkarni, Charchit Sharma, Deepak Vijaykeerthy, Vineeth N Balasubramanian
DMLR@ICML, 2024
description
We use Item Response Theory (IRT) to assess model calibration, select informative data subsets, and demonstrate the usefulness of various latent parameters for analyzing and comparing models and datasets in computer vision.
|
Stolen from Jon Barron's source code. |